Концепция реактивного программирования
Основная идея
Реактивность - это реагирование на изменения (в отличие от проактивнсти)
Реактивное программирование - это замена императивному выполнению кода “построчно”. В отличии от традиционного способа выполнения, когда код в потоке (треде) выполняется построчно без возможности вклиниться в это выполнение другому потоку, в РП выполнение делится на набор атомарных операций (коротких и по максимуму неблокирующих), и после выполнения одной операции (Publisher) результат передается следующей (Subscriber). Каждая из таких операций может выполняться на любом треде (про то, на каком именно треде будет выполняться, позже). То есть мы по факту разрываем построчное выполнение,выполняя каждую операцию по отдельности, и каждая операция является Subscriber’ом тех данных, которые ей нужны для ее выполнения, и Publisher’ом результата. Каждая такая операция должна быть неблокирующей, чтобы реактивщина действительно эффективно работала, не заставляя поток, на котором она работает, ждать какого-то события.
Последовательность операций и есть реактивный поток данных. Работа с потоками выводит эту обработку данных на новый уровень абстракции - мышление начинается не отдельными операциями, а едиными потоками, которые могут разделяться, фильтроваться, объединяться с другими и “перетекать” на другие планировщики тредов.
Итак, реактивное программирование - это асинхронность + потоковая обработка данных + неблокирующие операции.
Зачем это нужно
- Моментальное реагирование на изменения (что пригодилось в UI, например, широко используется в JS фреймворках)
- Потоковая обработка данных c большой параллелизацией
- Асинхронность без “callback hell” и прочих проблем
Составляющие
- Publisher - источник данных, который в какой-то момент (возможно) выдаст данные подписчику
- Subscriber - подписчик, который ожидает данных от publisher’а
- Subscription - сама подписка, с помощью которой можно сообщить publisher’у о том, что subscriber готов принять данные.
Собственная реализация
А теперь пора писать свою реализацию, чтоб разобраться, как эти 3 элемента и формируют более сложные вещи.
Publisher,Subscriber,SubscriptionJustPublisherCollectingSubscriber(+.collect()вPublisher‘е)MapPublisher(+.map(Function),.peek(Consumer))DeferredPublisher(+.defer(Supplier<Publisher>),.from(Supplier<V>))ConsumingSubscriber(+.consume(Consumer))ParallelPublisher(.parallel(n))
Важная вещь, которую стоит отметить. Добавление нового элемента не изменяет уже существующие, т.е. у нас почти все иммутабельно. Следование иммутабельности важно понимать, потому что то же самое будет и в готовых реализациях.
Минусы реактивного программирования
- Сложность дебага
- Сложность тестирования
- Высокий уровень абстракции может породить сложнообнаруживаемые ошибки при отсутствии полного понимания, как это работает под капотом
- Сложность разделения на методы, разделения обязанностей
- Проще создать потоковое голодание
Готовые реализации
Изначально появилась Reactive Streams Initiative, целью которой было стандартизовать
реактивщину. Они создали спецификацию Publisher/Subscriber/Subscription (и Processor, который просто является Publisher’ом и Subscriber’ом),
которая потом вошла в JDK в java.util.concurrent.Flow (Flow.Publisher, Flow.Subscriber, etc.).
Две наиболее используемые реализации реактивных потоков - это RxJava и Project Reactor. RxJava часто используется в Android-приложениях, тогда как Project Reactor используется в backend. RxJava называет Pub/Sub Observable/Observer, но в целом очень похожа на Project Reactor.
Project Reactor
Добавление в проект
Maven:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- ... -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-bom</artifactId>
<version>2020.0.6</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<!-- ... -->
</project>
Gradle:
dependencyManagement {
imports {
mavenBom "io.projectreactor:reactor-bom:2020.0.6"
}
}
dependencies {
implementation 'io.projectreactor:reactor-core'
testImplementation 'io.projectreactor:reactor-test'
}
Mono и Flux
Две главных составляющих Project Reactor - это Mono и Flux. Mono - это источник одного значения, а Flux - поток данных.
Холодные и горячие источники
Есть важная разница между этими двумя видами источников данных.
Подписчик горячего источника после подписки будет получать данные, идущие с момента подписки и далее (т.е. этот источник уже разогрет и транслирует данные). Например, если источник отдает числа от 1 до 10, то подписчик, подписавшийся после числа 6, получит только последние 3 числа.
Подписчик холодного источника получит данные с самого начала. Например, подписчик из предыдущего примера получит все 10 чисел.
Создание Mono / Flux
.just, .from, .fromIterable
Трансформация данных, обработка
.map- одно значение в другое.transform- преобразовать один Publisher в другой
Обработка событий
.doOnNext.doOnError.doOnComplete.doOnCanceldoOnSubscribe- и другие
Возврат к синхронной обработке
Flux:
.blockFirst.blockLast.toIterable.toStream
Mono: .block
Объединение нескольких источников
Flux.merge / .mergeWith, Flux.zip / .zipWith, Flux.combine и прочие.
Параллелизация
.parallel(), ParallelFlux
Но если не указать, где ему работать, то выполнение все равно будет в одном потоке.
Шедулеры
- single - однопоточный
- parallel - неблокирующие быстрые операции
- elastic - долгие операции, например, I/O
- boundedElastic - для ограничения возможного количества потоков (чтобы избежать потокового голодания)
- Собственные шедулеры (newSingle, newParallel, newBoundedElastic, другие) - чтобы избежать ситуации, когда две несвязанные операции замедляют друг друга из-за использования общего шедулера
Backpressure
Поскольку в этой модели Publisher “пихает” данные подписчику, может возникнуть ситуация, когда подписчик еще не готов обработать новые данные (чаще всего, когда источник очень быстрый, а обработчик - долгий). Такая ситуация называется backpressure (давление сзади). Существует несколько стратегий обработки такой ситуации:
.onBackpressureLatest, .onBackpressureDrop, .onBackpressureBuffer
Стратегии обработки ошибок
Есть несколько способов обрабатывать ошибки:
.onErrorContinue- продолжить выполнение, обработав ошибку.onErrorResume- перейти на другой поток-fallback.onErrorReturn- вернуть вместо errored значения fallback-значение и завершить.onErrorStop- прекратить выполнение
Тестирование
Основной класс для тестирования - это StepVerifier:
StepVerifier.create(source)
.expectNext("test1")
.expectNoEvent(Duration.ofSeconds(1000))
.expectNext("test2")
.expectNextCount(10)
.expectComplete()
.verify();
Дебаггинг
Необходимо включить режим Hooks.onOperatorDebug() в настройках IDEA.
Тогда stacktrace будет более подробным (но такой режим работает дольше).
Есть метод .log(), с помощью которого проще искать проблему
Sinks
Не во всех ситуациях подходит иммутабельность потоков, необходимо динамически что-то добавлять во Flux. Для этого есть специальный инструмент, который называется Sink
Есть несколько видов sink’ов. Создаются они через Sinks.one() / Sinks.many()
и превращаются в Mono/Flux через .asMono / .asFlux
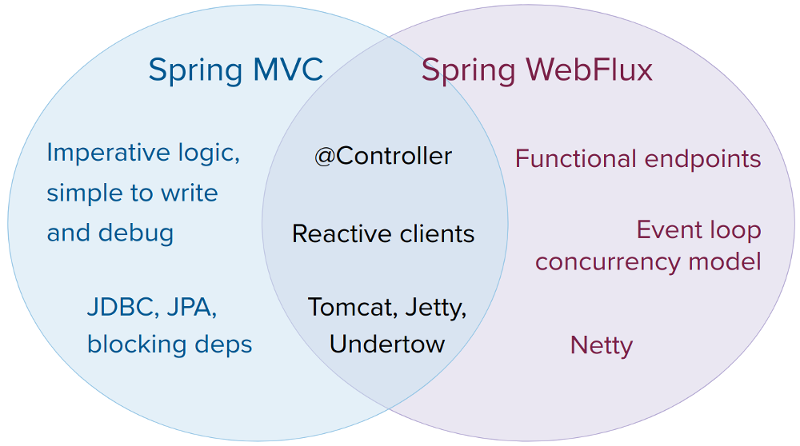
Spring WebFlux
На основе Project Reactor Spring создал реактивный web-фреймворк.
Добавление в проект
Будем считать, что вы используете Spring Boot и вам не нужно извращаться с кучей настроек
Для Maven:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
Для Gradle:
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-webflux'
testImplementation 'io.projectreactor:reactor-test'
}
Web-контроллеры
Spring WebFlux поддерживает контроллеры с теми же аннотациями, что и обычные у обычных Web MVC контроллеров:
@RestContoller
public class MonoController {
@GetMapping("/hello")
public Mono<String> hello(@RequestParam String name) {
return Mono.just("Hello, " + name);
}
}
Функциональные endpoint’ы
Помимо обычных контроллеров, WebFlux позволяет регистрировать enpoint’ы функционально:
@Configuration
public class CalculationRouter {
@Bean
public RouterFunction<ServerResponse> calculationRoutes(CalculationHandler handler) {
return RouterFunctions
.route()
.POST("/api/v1/calculations/unordered", handler::calculateUnordered)
.POST("/api/v1/calculations/ordered", handler::calculateOrdered)
.build();
}
}
@Component
public class CalculationHandler {
private final CalculationSeriesService seriesService;
public CalculationHandler(CalculationSeriesService seriesService) {
this.seriesService = seriesService;
}
public Mono<ServerResponse> calculateUnordered(ServerRequest request) {
Mono<CalculationRequest> bodyMono = request.bodyToMono(CalculationRequest.class);
return bodyMono.flatMap(calculationRequest ->
ServerResponse.ok()
.contentType(MediaType.TEXT_EVENT_STREAM)
.body(
seriesService.calculateUnordered(
calculationRequest.getFunction1(),
calculationRequest.getFunction2(),
calculationRequest.getCount())
.map(UnorderedCalculationResult::getDataAsString)
.onErrorResume(ExecutionTimeoutException.class,
ex -> Mono.just("EXECUTION TIMEOUT"))
.onErrorResume(FunctionExecutionException.class,
ex -> Mono.just("EXECUTION " + ex.getExecutionId() + " ERROR"))
.onErrorReturn(Predicate.not(e -> e instanceof FunctionEvaluationException),
"EXECUTION ERROR"),
String.class
)
);
}
public Mono<ServerResponse> calculateOrdered(ServerRequest request) {
Mono<CalculationRequest> bodyMono = request.bodyToMono(CalculationRequest.class);
return bodyMono.flatMap(calculationRequest ->
ServerResponse.ok()
.contentType(MediaType.TEXT_EVENT_STREAM)
.body(
seriesService.calculateOrdered(
calculationRequest.getFunction1(),
calculationRequest.getFunction2(),
calculationRequest.getCount())
.map(OrderedCalculationResult::getDataAsString)
.onErrorResume(ExecutionTimeoutException.class,
ex -> Mono.just("EXECUTION TIMEOUT"))
.onErrorResume(FunctionExecutionException.class,
ex -> Mono.just("EXECUTION " + ex.getExecutionId() + " ERROR"))
.onErrorReturn(Predicate.not(e -> e instanceof FunctionEvaluationException),
"EXECUTION ERROR"),
String.class
)
);
}
}
SSE
При возврате Flux’а как ответа сервера Spring преобразует ответ в формат Server-side event’ов (SSE).
SSE удобны, когда нужен односторонний стриминг данных или уведомления о событиях
(в одну сторону, в отличие от web socket’ов).
Content type у ответов может быть либо text/event-stream (официальный тип для SSE),
либо application/stream+json (deprecated for streaming JSON by Spring)
SSE по спецификации только на POST-запросы